Improving RAG Applications with Semantic Caching and RAGAS
By Kyle Banker
If you’ve started down the path of building RAG applications, you’re likely familiar with some of the challenges of selecting the right LLM, vector database, embedding API, and RAG framework. Once you have these choices dialed in, you’ll want to consider the performance and correctness of your RAG architecture. After all, LLM calls aren’t known for being fast. And even if they are sufficiently performant, your RAG pipeline might not be providing the most relevant responses to your users. We’ve found this to be especially true when building RAG applications for users working across diverse domains; what works in a legal setting might not be appropriate in medical or retail-based applications.
This article introduces two techniques for improving your RAG applications. Semantic caching is a way of boosting RAG performance by serving relevant, cached LLM responses, thus bypassing expensive LLM invocations. RAGAS is a framework for testing the quality of RAG application responses. If we find that our RAG application’s answers are sub-par, we can experiment with adjusting the parameters of our RAG pipeline and then retest its correctness.
To get familiar with semantic caching and RAGAS, let’s look at them in the context of a real, runnable example: the Redis RAG Workbench.
Introducing the Redis RAG Workbench
Redis is commonly used as a vector database in RAG architectures. The reason is that Redis vector search is fast. This speed is especially relevant when implementing semantic caching. To see why this might be so, we can turn to an actual RAG application. We built the Redis RAG Workbench to give our users a visual interface for experimentation with common RAG application settings using arbitrary documents. The workbench is build with the following underlying tools:
- LangChain (with the langchain-redis package)
- The Redis Vector Library for Python (a.k.a., RedisVL)
- The Python RAGAS framework
- LLMs and embeddings APIs from OpenAI, Cohere, and HuggingFace
Here’s a screenshot of a running application:
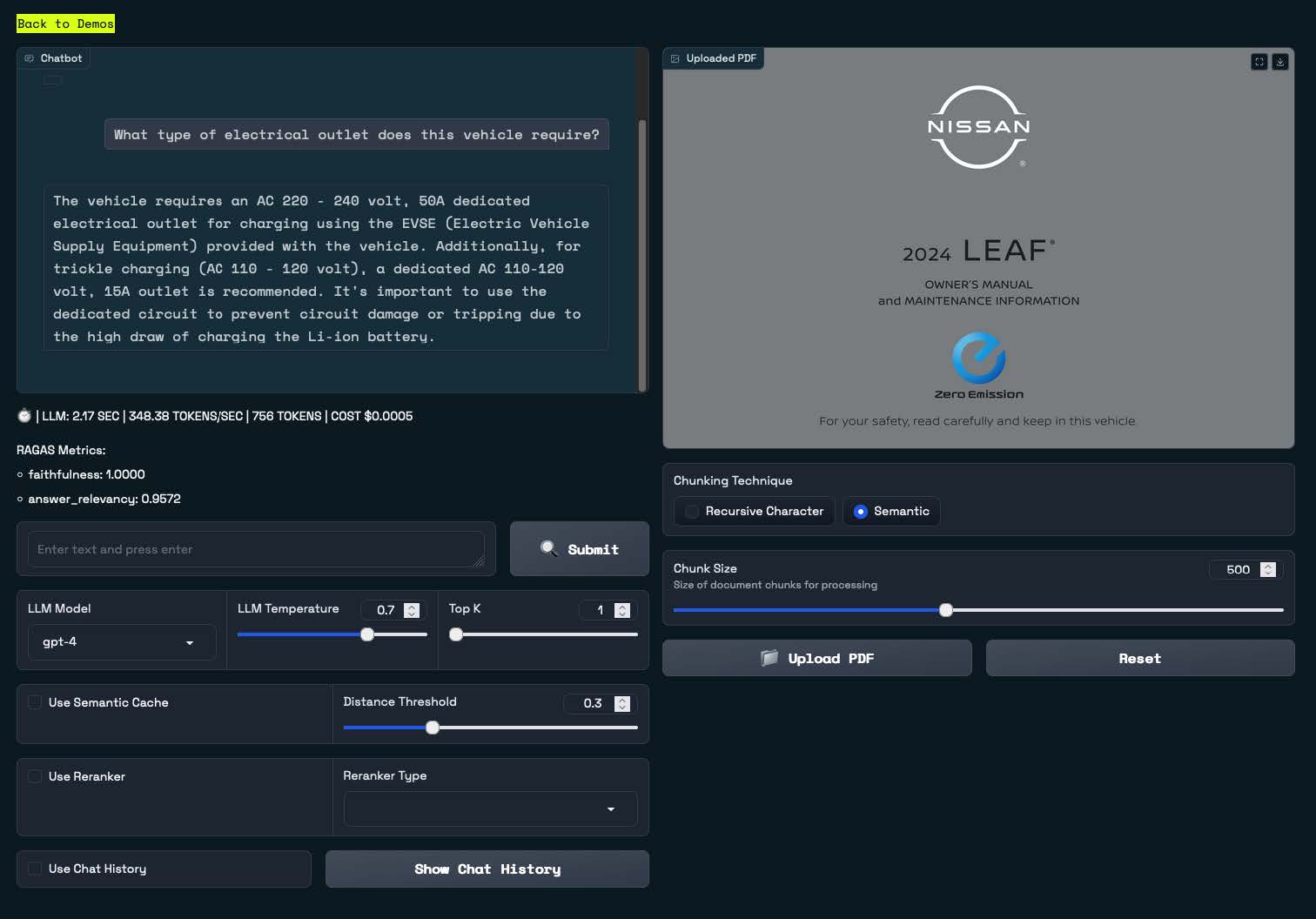
The workbench lets you upload a PDF and then provides a chat interface for answering questions about what’s inside. In the example here, we’ve uploaded the owner’s manual for a popular electric vehicle (the Nissan LEAF®). You can also see that we’ve asked a common question in the chat interface: “What type of electrical outlet does this vehicle require?”. The application has replied with a relevant excerpt from the manual.
The real power of this RAG workbench is that it allows you to experiment with a variety of RAG pipeline settings. These include how to split up the uploaded PDF (chunk size and chunking technique) and which LLM to use (e.g., GPT-4). You can also enable a semantic cache.

When you enable semantic caching, the workbench creates an entry in the underlying Redis vector database for each question-answer pair entered in the chat. For example, notice in the previous response that this electric vehicle features a “trickle” charging mode. So, suppose we ask the following question: “What’s the difference between normal charging and trickle charging?”
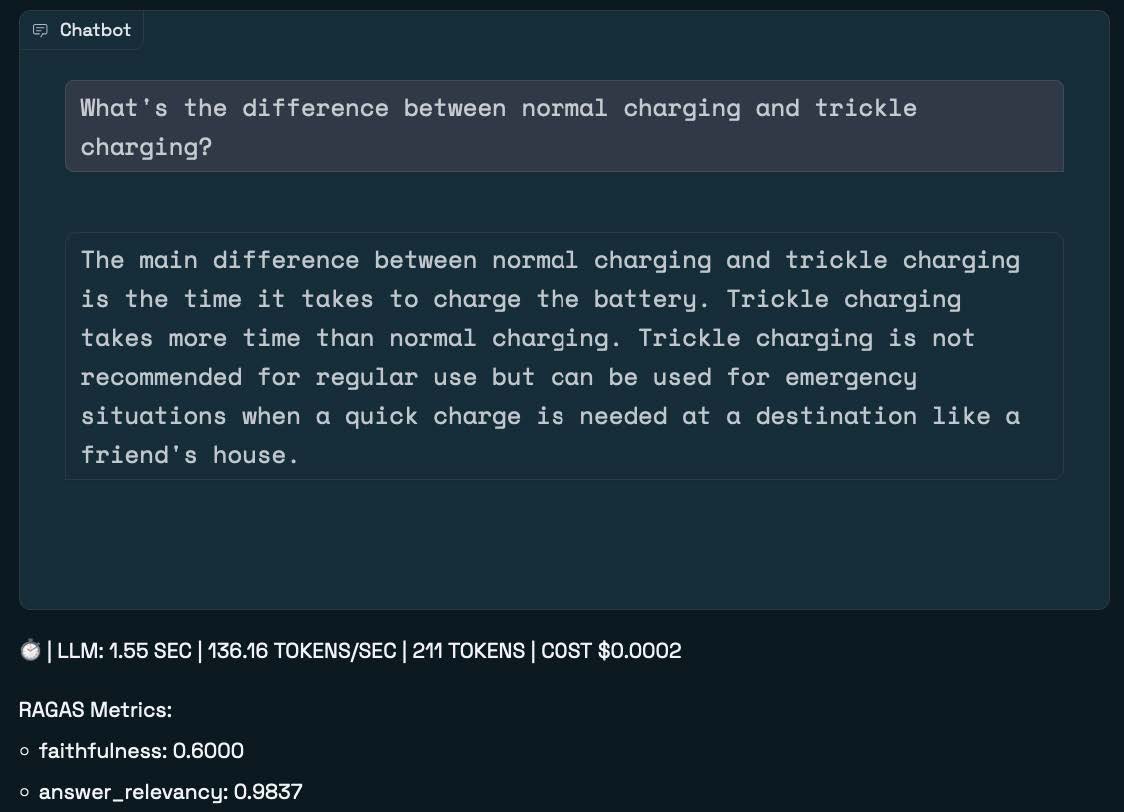
The workbench returns a response that makes sense, but we also see some data on how long the LLM call took, the number of tokens processed, and the dollar cost of calling the LLM. While the cost is only fractions of a cent, we know that in a real-world system with lots of traffic, the cost will start to add up.
You’ll also notice some RAGAs metrics, indicating the quality of the response (more about this below).
So let’s now ask another question with the same meaning. Maybe, “What’s the difference between trickle charging and normal charging?” (Notice, I’ve switched up the word order).
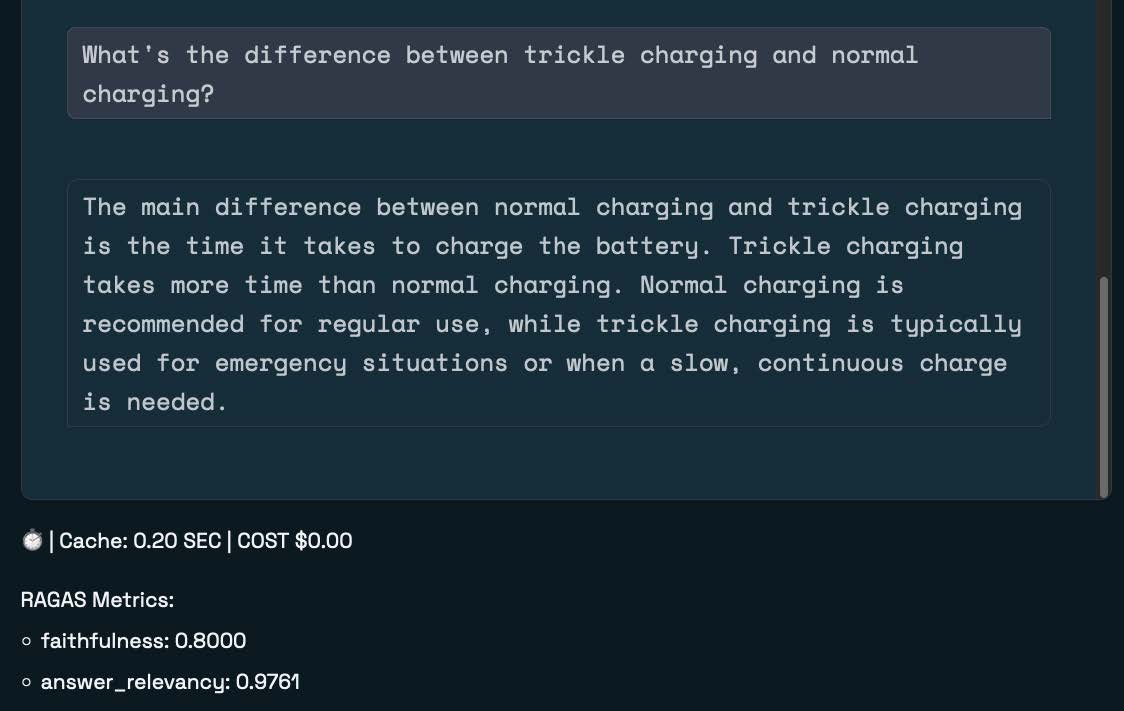
This time, the response bypasses the LLM completely. Internally, the workbench still has to create an embedding and search our vector database, but:
- The response time is significantly decreased, and
- The LLM cost is $0.00
This is semantic caching in action! And, happily, the “answer_relevancy” RAGAS metric is exceptional (scoring 0.9761, with the highest possible score of 1).
To test this out for yourself, try installing the Redis RAG Workbench locally and uploading a PDF of interest. The project is open source, so you can examine the code and see how our applied AI team built the app. Since our purpose here is to dive more deeply into semantic caching and RAGAs, let’s now examine these topics in more detail.
Semantic caching
Recent research into semantic caching indicates that up to 31% of all LLM calls may be redundant. Semantic caching may reduce those redundant calls by a large margin, resulting in faster response times and lowered LLM inferencing costs. To help you exploit this opportunity and get to production more quickly, we’ve built a SemanticCache interface into the Redis Vector Library (RedisVL). This interface uses Redis’s vector search to store question-answer pairs and provide responses to semantically-similar questions.
Let’s look at some example code to see how this works. These examples are taken from Tyler Hutcherson’s awesome Jupyter notebook, so if you want to go straight to a runnable source, start there.
We’ll start by writing a method that calls OpenAI and responds to user prompts.
import os
import getpass
import time
import numpy as np
from openai import OpenAI
os.environ["TOKENIZERS_PARALLELISM"] = "False"
api_key = os.getenv("OPENAI_API_KEY") or getpass.getpass("Enter your OpenAI API key: ")
client = OpenAI(api_key=api_key)
def ask_openai(question: str) -> str:
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=question,
max_tokens=200
)
return response.choices[0].text.strip()We can test this method by asking a simple question:
# Test
print(ask_openai("What is the capital of France?"))The printed response will of course be “Paris”.Next, we’ll initialize a SemanticCache object:
from redisvl.extensions.llmcache import SemanticCache
llmcache = SemanticCache(
name="llmcache", # underlying search index name
redis_url="redis://redis.cloud:6379", # Redis connection url
distance_threshold=0.1 # semantic cache distance
)Once initialized, the SemanticCache will automatically create a Redis index for the semantically cached question-answer pairs.
RedisVL includes a command line tool that lets you examine the indexes created in Redis. From the command line, run:
$ rvl index info -i llmcacheThis will print a table of all of the indexes created thus far. Here, we’ll see that the newly created index has fields for the prompt, the vectorized prompt, the response, and the created and updated timestamps. To use the cache, we can call the check() method, passing in the prompt (or question). For example:
# Store the user's question
question = "What is the capital of France?"
# Check the semantic cache -- should be empty
if response := llmcache.check(prompt=question):
print(response)
else:
print("Empty cache")Initially, the cache will be empty. So, after calling the LLM, we’ll store the question and answer:
# Cache the question, answer, and arbitrary metadata
llmcache.store(
prompt=question,
response="Paris",
metadata={"city": "Paris", "country": "france"}
)Now that the question is stored, we’ll get a response when we check the cache with other questions having meanings similar to “What is the capital of Paris?”. For instance:
# Check for a semantically similar result
question = "What actually is the capital of France?"
llmcache.check(prompt=question)[0]['response']This call to the cache will return “Paris”. But so will calls that ask:
- What’s the capital of France?
- What’s France’s capital?
- What is the capital city of France?
If we want to experiment with allowing an even wider range of questions, we can adjust the “semantic threshold” of the cache.
# Widen the semantic distance threshold
llmcache.set_threshold(0.3)With this widened similarity threshold, we can ask a more circuitous version of the same question. Now the cache will return “Paris” when asked, “What is the capital city of the country in Europe that’s also home to the city of Nice?”.
If you’d like to explore RedisVL’s semantic cache abstraction further, you can find all of this code and more in our sample Jupyter notebook.
RAGAS
We’ve talked about improving the performance of RAG applications using semantic caching. But what about correctness? RAGAS (Retrieval Augmented Generation Assessment) is a framework for automatically evaluating the quality of the answers provided as part of a RAG architecture. The RAGAS framework provides three metrics:
- Faithfulness measures the degree to which claims that are made in an answer can be inferred from the provided context.
- Answer relevance measures how directly and appropriately the question itself is answered. This question penalizes hallucinations.
- Context relevance measures the extent to which answers exclusively contain the information needed to answer the question. This metric aims to penalize the inclusion of redundant information in the response.
The authors of the RAGAS paper have released a Python framework that assists in performing these evaluations. We’ve found this extremely useful in architecting the most useful RAG applications with our users.
To get you started, we’ve put together a RAGAS and Redis Jupyter notebook that explores some of the basic workings of the framework. In this example, we build a RAG pipeline that evaluates questions and answers about a recent Nike SEC filing.
Recap and next steps
A working RAG pipeline is just the first step in building generative AI applications suitable for production. We’ve found that semantic caching increases the performance of these applications, while RAGAS helps us to effectively evaluate the quality of our RAG systems’ outputs. If you’re new to these techniques, we highly recommend checking out some of the resources we’ve recently built:
- Our Redis RAG Workbench lets you chat with any PDF, tweak your RAG settings, experiment with semantic caching on Redis, and review RAGAS metrics for each question-answer interaction. The project is open source, and its brilliant creator, Mr. Brian Sam Bodden, would love your feedback and PRs.
- To make it easier to get started with semantic caching, we’ve shipped a semantic cache abstraction as part of the RedisVL Python library. The semantic cache docs are quite complete, but the Jupyter notebook should be your first port of call.
- We’ve found the RAGAS framework to be essential for optimizing the quality of our RAG apps. You can see a complete example of evaluating Redis RAG pipelines with RAGAS (say that 10 times fast!) in the associated Jupyter notebook. Our applied AI engineer Robert Shelton has also written a great blog explaining how RAGAS works.
Lastly, and this is a totally shameless plug, if you’re interested in learning more about where Redis sits in the generative (and classical) AI world, our Redis AI Resources Github repo is an always-up-to-date trove of examples and tools. If you find this useful, we’d love to hear from you. Catch us in person at All Things Open or on the Redis Discord server.
The Featured Blog Posts series highlights posts from partners and members of the All Things Open community leading up to ATO 2024.